
- 새로운 뉴스를 올려주세요.
| Date | 22/07/08 22:19:49 |
| Name | 구밀복검 |
| File #1 | 41562_2022_1383_Fig1_HTML.webp (240.0 KB), Download : 50 |
| Subject | 구글의 '민주적 AI'는 미국보다 재분배를 잘합니다. |
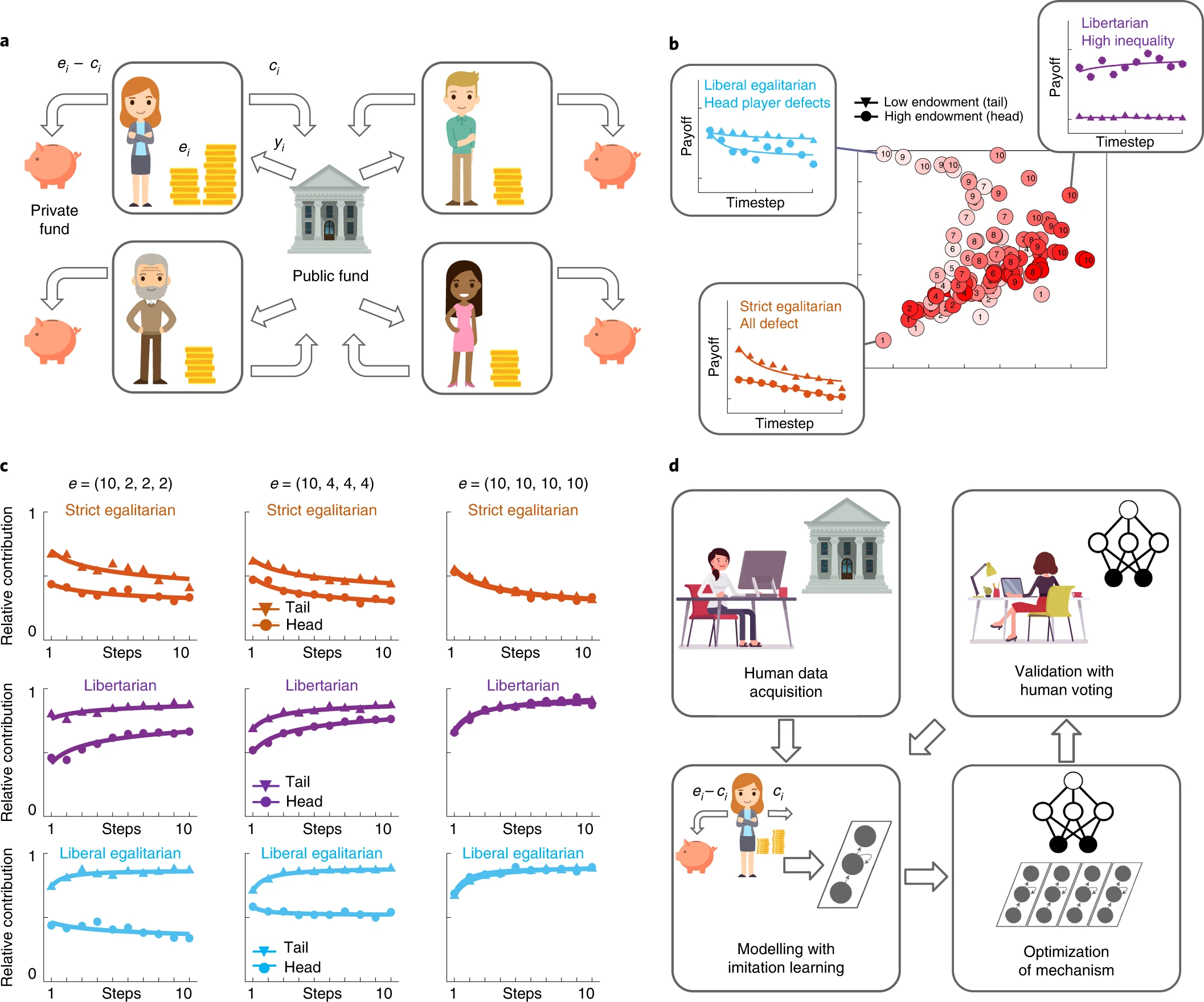 https://www.vice.com/en/article/z34xvw/googles-democratic-ai-is-better-at-redistributing-wealth-than-america https://www.nature.com/articles/s41562-022-01383-x 연구는 다음과 같습니다. '공공재 게임'이라는 경제 게임에 인간 플레이어들이 참여하게 합니다. 게임은 총 34라운드가 반복되는데, 각 라운드마다 개인 계정에 현재의 자산을 유지할 것인지 아니면 공적 기금에 증여할 것인지 선택하게 했습니다. 공적 기금은 재분배가 되게끔 설계되어 있는데, 이때 이 공적 기금의 재분배를 어떤 방식으로 할지가 게임의 관건이 되었습니다. 이번 연구에서는 이 재분배 절차를 복수의 시스템들이 수행하게 한 다음, 어느 시스템이 가장 자원을 적절하게 분배했는지를 해당 게임에 참여한 인간 플레이어들의 투표를 가리기로 했다고 합니다. 구글 딥마인드의 심층신경망은 '인간 중심 분배 기제'를 채택하여 자유지상주의 체계와 평등주의적 체계와 경합을 펼쳤는데, 결과적으로 가장 많은 인간 참여자들에게 지지를 받아 게임에서 승리했다고. "광범위한 자유주의 평등성 정책을 추구하면서 인간 중심 분배 기제는 기부금에 대한 기여도에 비례하여 플레이어를 보상함으로써 기존의 소득 격차를 줄이려고 했다. 다시 말해, 단순히 효율성을 극대화하지 않았으며, 기제는 진보적이었다. 그것은 자산 박탈 상태에서 게임을 시작한 사람들의 권한을 증진시켰으며, 초기 자산이 더 높았던 이들을 희생시켰다.(Pursuing a broadly liberal egalitarian policy, [HCRM] sought to reduce pre-existing income disparities by compensating players in proportion to their contribution relative to endowment.. In other words, rather than simply maximizing efficiency, the mechanism was progressive: it promoted enfranchisement of those who began the game at a wealth disadvantage, at the expense of those with higher initial endowment.)" 인간 플레이어들의 피드백을 기계학습에 반영하여 기계에게 민주적 분배 방식을 학습시킬 수 있었다는 점이 핵심. 1
이 게시판에 등록된 구밀복검님의 최근 게시물
|
|
