
- 다양한 주제에 대해 자유롭게 글을 작성하는 게시판입니다.
| Date | 18/05/18 00:25:43 |
| Name | 다시갑시다 |
| Subject | 본격(영어)듣기시험 평가 얘니 v 로렐 분석 |
|
일단 클릭부터하신 주도적인분들은 이글을 참조하시고 오시면 되겠습니다: https://redtea.kr/?b=13&n=30960 이글의 작성시작 시점에서 댓글과 추천수를 추려본 결과 얘니파가 13분 로렐파가 6분입니다 (저 포함) 그리고 저주파수와 고주파수에서 다른 발음을 하는것 같다고 언급하신 헬리제의우울님이 계셨습니다. 가장 정답에 가까운 댓글이라 생각하는데, 왜 그런지를 조금 풀어보겠습니다. 다만 헬리제의우울님의 댓글로 돌아가보면, 이러한 분석을해볼수있습니다. 오디오튜닝 소프트웨어를 사용하면 특정주파수의 음파를 강조하거나 줄일수가있습니다. 논라의 오디오에서 저주파수를 줄이고 고주파수만 살리거나, 반대로 저주파수만 살리고 고주파수를 줄이면 어떻게 될까요? https://twitter.com/thetravisnewton/status/996502177232359426 사람과 환경마다 다르기는하지만, 고주파수만 살아있을 경우 Yanny에 가깝게 들리고, 저주파수만 살아있을 경우 Laurel로 들리는 경향이 나타납니다. 그렇다면 누군가가 Yanny와 Laurel을 둘다 녹음하고 섞어서 사람들을 햇갈리게 만들고있는걸까요? 그건 아니라고합니다. 우연히 발견된 오디오 클립인데, 이 클립의 원본은 https://www.vocabulary.com/dictionary/laurel 이 웹사이트에서 단어발음을 가르켜 주는 인공지능이 Laurel의 발음을 최대한 흉내낸것이라고 알려져있습니다. 누군가를 햇갈리기 위해 의도적으로 만들어진게 아니라, 우연히 이러한 청각적 착시 클립이 만들어진거죠. 그렇다면 도대체 이 인공지능이 무엇을 하였길래 이 음성파일이 다르게 들리는걸까요? 이를 이해하기 위해서는 음성학적인 분석이 필요합니다. 사실 전 음성학에 전혀 모르지만, 제가 이런 연구를 하는분들의 트위터와 위키피디아를 훑어 보며 이해한대로 풀어보겠습니다. 중요한 개념은 [포먼트/formant]라고 합니다. 사람의 발성을 주파수를 기준으로 그래프를 그리면 특정한 분포를 보입니다. 그리고 어떠한 소리를 내고있었는지에 따라 어떤 주파수가 강조되는지가 다릅니다. 강조된 이 주파수들을 포먼트라고 부릅니다. 성대의 사이즈에 따라서 정확히 어떤 주파수가 강조되는지는 변할수있지만, 같은 소리를 내고있었다면 강조되는 주파수의 분포는 동일하다고합니다. 예를 들어 성대가 긴편인 제가 200Hz와 1600Hz를 울려서 내는 소리는, 성대가 짧은편인분이 215Hz와 1720Hz를 울려내는 소리와 같다는거죠, 차이는 순전히 음정에 있는거고요. 이게 정확한 해석이 아닐수도있지만 전 일단 대충 이렇게 이해하고있습니다. 조금 더 세분화 시켜서: 가장 낮은 주파수의 울림을 F1 (포먼트1), 그 다음으로 강조되는 울림을 F2(포먼트2)이런식으로 지칭합니다. 소리에 따라 F3, F4, F5... 계속 나갈수있지만 보통 F3 이상의 고주파수는 사람의 목소리에서 신경쓸일은 없는것 같고, 모음은 F1과 F2만으로도 구분 가능한 경우가 굉장히 많기 때문에 F1과 F2만으로도 많은 분석이 가능하다고합니다. 그리고 음성학자들이 이걸 마니마니 분석해서 이런 표도 만들고 그런거죠 (위키피디아에 Formant 검색하면 나옵니다). 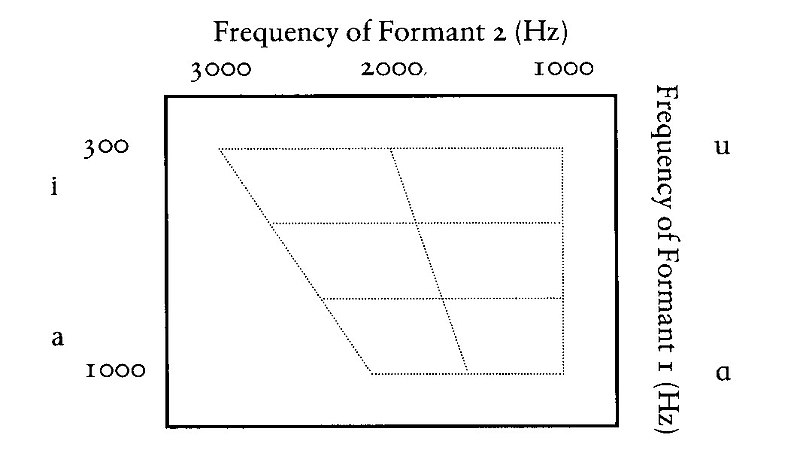 문제가 간단해졌죠? 이 음성파일에 포먼트를 분석을해서 F1과 F2가 어떻게 분포되어있는지 보면 되는거죠. 근데 인생이 그렇게 만만한게 아닙니다. 음성파일의 포먼트를 분석해본 결과 흥미로운점이 발견되었습니다 (뚜-둔) 이 음성파일은 강조되는 주파수가 두군데라고합니다. 저주파수 지역에 여러 주파수를 넓게 두르며 강조되는 지역과, 고주파수 지역에서 적은수의 주파수만 강조되는 지역 2군데라는거죠. 그리고 이 특성이 바로 이 청각착시 효과를 이르키는 이유라고합니다. 이 주파수 패턴을 우리의 뇌가 어떻게 이해하느냐의 문제라는거죠. (단순히 뇌의 문제뿐만 아니라 이 오디오 파일이 재생된 여건 등 다른 외부적인 요소의 개입도 생각해보아야하긴합니다) 만약에, 저 주파수의 넓게 강조된 부분을 "아 이건, F1과 F2가 매우 비슷한 주파수를 띄고있는거야"라고 이해를 한다면 우리의 뇌는 이것을 "Laurel"의 첫 모음인 [/a/]로 해석을하고 그렇다면 고주파수 지역을 F3으로 해석하는데, 이는[/ɹ/!], 즉 "Laurel"의 자음의 소리로 들리게됩니다. 그리고 F3도 상대적으로 고주파수이지만 다른 F3에 비해서는 낮은편이기에 이를 중저음의 남성이 발음하는 것으로 해석을하게됩니다. 그런데, 조금 다르게 생각해볼수도있습니다. 저주파수의 넓게 강조된 부분을 그냥 넓은 F1으로 , 그리고 고주파수 지역을 F2로 이해해버리면 어떻게 될까요? 이럴 경우 이는 상대적으로 굉장히 높은 주파수의 F2로 해석이됩니다. 이렇게 높게 위치한 F2는 주로 첫 음절이 모음일때 자주 나타나는 현상이죠, 이 경우 F1의 특성과 결합해서 보면 [/jae/] ("얘이")의 발음과 매우 비슷한 형태를 보입니다. 이렇게 해석할 경우 "Yanny"가 들리는거죠. 동시에 전체적으로 고주파수 음정으로 해석을하기에 이 오디오는 남성적인 목소리보다는 성별이 좀 애매모호한, 약간 코맹맹한 소리로 해석될 가능성이 높다고합니다. 그렇다면 사람들이 왜 이걸 다르게 해석할수있는걸까요? 오디오 장비와 같은 다른 요소들이 동일하다고 가정해도 소리를 해석하는데 개별적 차이가 존재한다고 믿을만한 연구가있다고합니다. 수학이나 물리를 많이 하신분들이라면 이 포먼트들이 resonance/harmonics에 기반한것이라는것을 눈치채셨을수도 있을것 같습니다. 방금 이과 망해라를 외치셨다면? 화음을 생각하시면됩니다. 자 이제 음악하시는 분들 나오실 차례입니다! (전 잘 모릅니다 ㅋ) 화음의 신비 중 하나는, 사람은 실제로 연주되지 않은 음을 들을수도있다는 것입니다. 인간은 반복되는 패턴을 찾아내고 이를 기반으로 추론(extrapolate)해내는 능력이 매우 뛰어난 동물입니다. 자 다 같이 해보죠: ...,3, 5, 7... 7 다음숫자는? 9! 3 이전숫자는? 1! 실제로 쓰여있지도 않은 숫자들을 패턴을 알아챔으로서 쉽게 상상해내신겁니다. 소리를 들을때, 저 포먼트도 비슷한 현상을 띌수가있다고합니다. F1, F2, F3의 패턴을 분석해보면, F1보다 한단계 아래의, F0라는 저주파수 소리 또한 추론해볼수있습니다. F0 주파수에 소리가 실존하든 하지 않든, 우리의 뇌는 F1, F2, F3을 보고 "아 이러면 F0도 존재해야하는구나"라고 생각할수있다는거죠. 그런데 사람에 따라 이 F0를 상상하고 듣는 능력에 차이가있다는 연구결과가있다고합니다. (여기서부터는 https://twitter.com/_roryturnbull 교수님의 개인연구 내용입니다). 그리고 아마 이 능력의 차이가 Yanny와 Laurel의 차이로 이어지는것이 아닌가 턴불교수는 질문합니다. F0를 더 잘 상상해내는 사람이라면 저주파수에 집중하기에 Laurel에 가깝게 들을것이고, 실제로는 있지도 않은 F0 따위, 실존하는 주파수들에 집중하는 사람들은 고주파수에 더 집중해서 Yanny에 가깝게 들을수있다는거죠. 턴불교수는 전자를 F0 리스너, 후자를 스펙트럴 리스너라고 명명하더군요 ㅋㅋ 파검/흰금 논란이 일었던 드레스와 결론은 비슷합니다. 흔히 우리의 오감을 통한 정보를 절대적 정보로 인지하는 경향이있지만, 사실 우리가 세상을 인지하는 법은 그보다 훨씬 복잡하고 뉘앙스가 많다는거죠. 드레스의 경우 시각적인 정보의 해석에 대해서 들여다볼수있는 기회였고, 얘니/로렐의 경우 청각적인 정보해석에 대해서 귀기울여볼수있었던것 같습니다. 똑같은 시간에 똑같은 곳에 있었어도, 다른 사람들의 현실은 나의 현실과 판이하게 다를수있다는거죠. 사실 전문지식을 이용해 설명해야하는걸 일반인이 몇일 훑어본 내용으로 적은거라 오류가 산재해있을터이니, 다른 비전문가분들은 감안하고 읽으시고, 전문가분들은 댓글이나 쪽지를 통해 잘못된점을 지적해주시면 최대한 빨리 수정하도록하겠습니다. 감사합니다. 다들 다음부터는 로렐을 들을수있기를 바라며 글을 마치겠습니다. 5
이 게시판에 등록된 다시갑시다님의 최근 게시물
|
|


